GUDHI Python modules documentation¶

Data structures for cell complexes¶
Cubical complexes¶
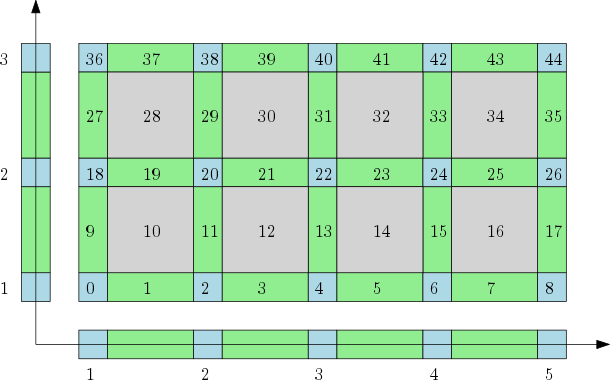
|
The cubical complex represents a grid as a cell complex with cells of all dimensions. |
|

|
|
|

|
|
|
Simplicial complexes¶
Simplex tree¶
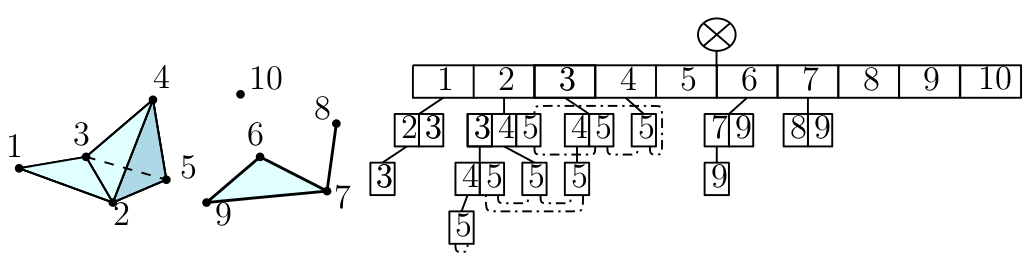
|
The simplex tree is an efficient and flexible data structure for representing general (filtered) simplicial complexes. The data structure is described in [5] |
|
|
|
|
|
Filtrations and reconstructions¶
Alpha complex¶
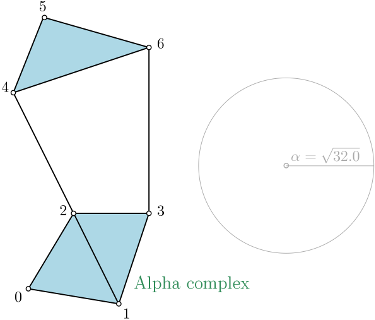
|
Alpha complex is a simplicial complex constructed from the finite cells of a Delaunay Triangulation. It has the same persistent homology as the Čech complex and is significantly smaller. |
|
Rips complex¶
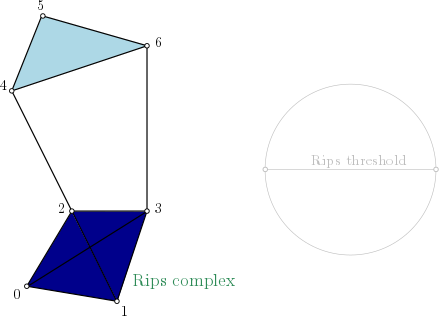
|
The Vietoris-Rips complex is a simplicial complex built as the clique-complex of a proximity graph. We also provide sparse approximations, to speed-up the computation of persistent homology, and weighted versions, which are more robust to outliers. |
|
|
|
|
|
Witness complex¶
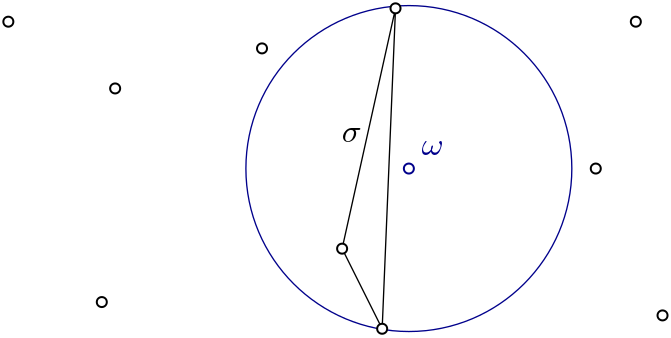
|
Witness complex \(Wit(W,L)\) is a simplicial complex defined on two sets of points in \(\mathbb{R}^D\). The data structure is described in [5]. |
|
Cover complexes¶

|
Nerves and Graph Induced Complexes are cover complexes, i.e. simplicial complexes that provably contain topological information about the input data. They can be computed with a cover of the data, that comes i.e. from the preimage of a family of intervals covering the image of a scalar-valued function defined on the data. |
|
Tangential complex¶
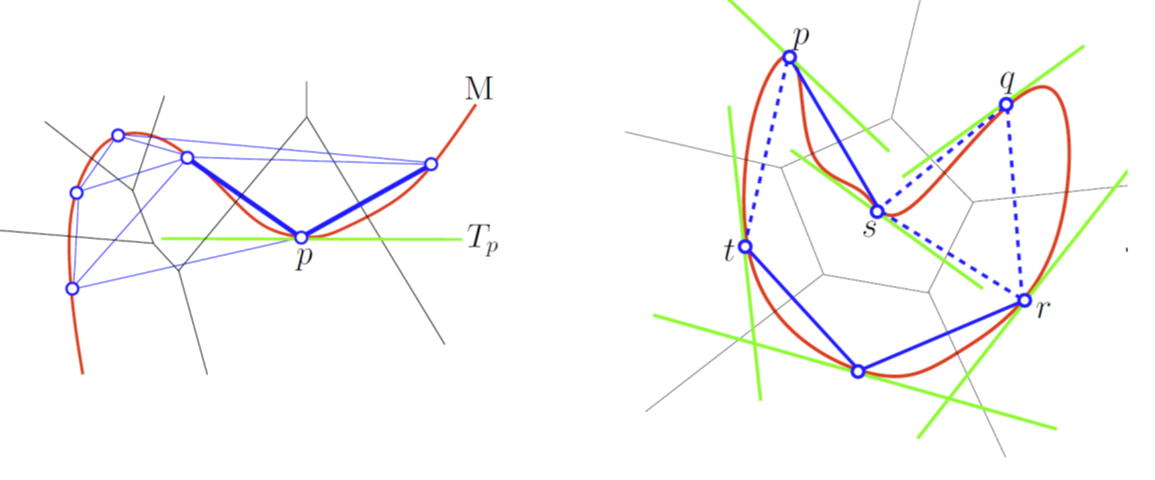
|
A Tangential Delaunay complex is a simplicial complex designed to reconstruct a \(k\)-dimensional manifold embedded in \(d\)-dimensional Euclidean space. The input is a point sample coming from an unknown manifold. The running time depends only linearly on the extrinsic dimension \(d\) and exponentially on the intrinsic dimension \(k\). |
|
Topological descriptors computation¶
Persistent cohomology¶
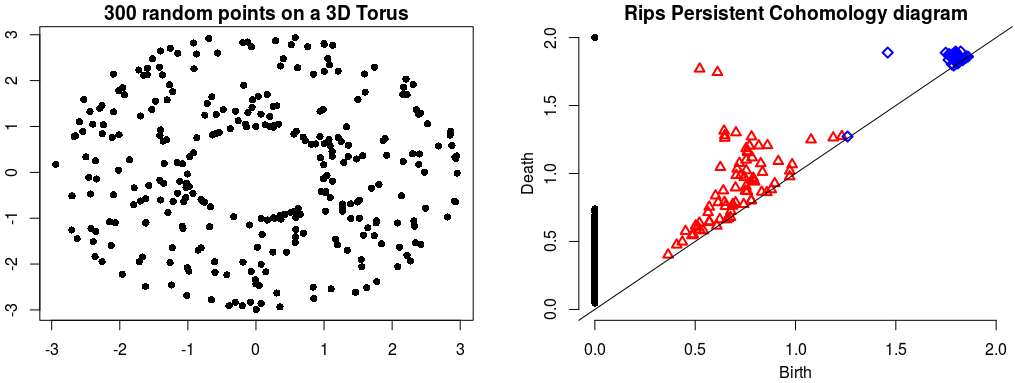
Rips Persistent Cohomology on a 3D Torus¶ |
The theory of homology consists in attaching to a topological space a sequence of (homology) groups, capturing global topological features like connected components, holes, cavities, etc. Persistent homology studies the evolution – birth, life and death – of these features when the topological space is changing. Computation of persistent cohomology using the algorithm of [15] and [18] and the Compressed Annotation Matrix implementation of [3]. |
|
Please refer to each data structure that contains persistence feature for reference: |
||
Topological descriptors tools¶
Bottleneck distance¶
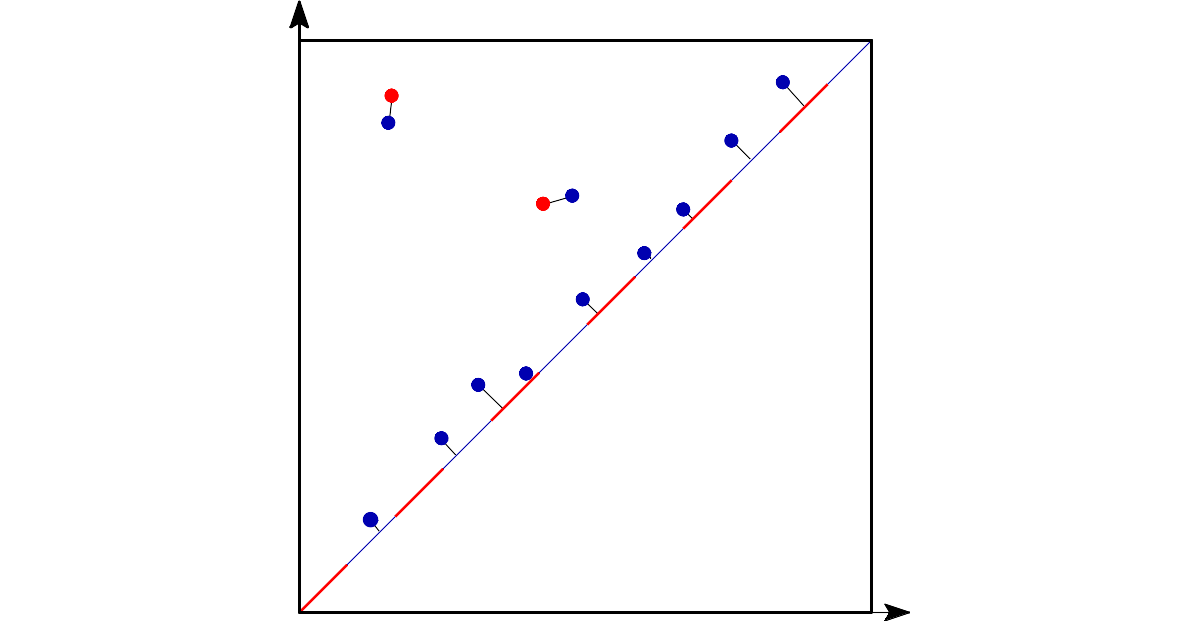
Bottleneck distance is the length of the longest edge¶ |
Bottleneck distance measures the similarity between two persistence diagrams. It’s the shortest distance b for which there exists a perfect matching between the points of the two diagrams (+ all the diagonal points) such that any couple of matched points are at distance at most b, where the distance between points is the sup norm in \(\mathbb{R}^2\). |
|
Wasserstein distance¶
|
|
The q-Wasserstein distance measures the similarity between two persistence diagrams using the sum of all edges lengths (instead of the maximum). It allows to define sophisticated objects such as barycenters of a family of persistence diagrams. |
|
Persistence representations¶
|
Vectorizations, distances and kernels that work on persistence diagrams, compatible with scikit-learn. |
|
Persistence graphical tools¶

|
These graphical tools comes on top of persistence results and allows the user to display easily persistence barcode, diagram or density. Note that these functions return the matplotlib axis, allowing for further modifications (title, aspect, etc.) |
|
Point cloud utilities¶
\((x_1, x_2, \ldots, x_d)\)
\((y_1, y_2, \ldots, y_d)\)
|
Utilities to process point clouds: read from file, subsample, find neighbors, embed time series in higher dimension, estimate a density, etc. |
|
Clustering¶

|
Clustering tools. |
|
Datasets¶
|
Datasets either generated or fetched. |
|